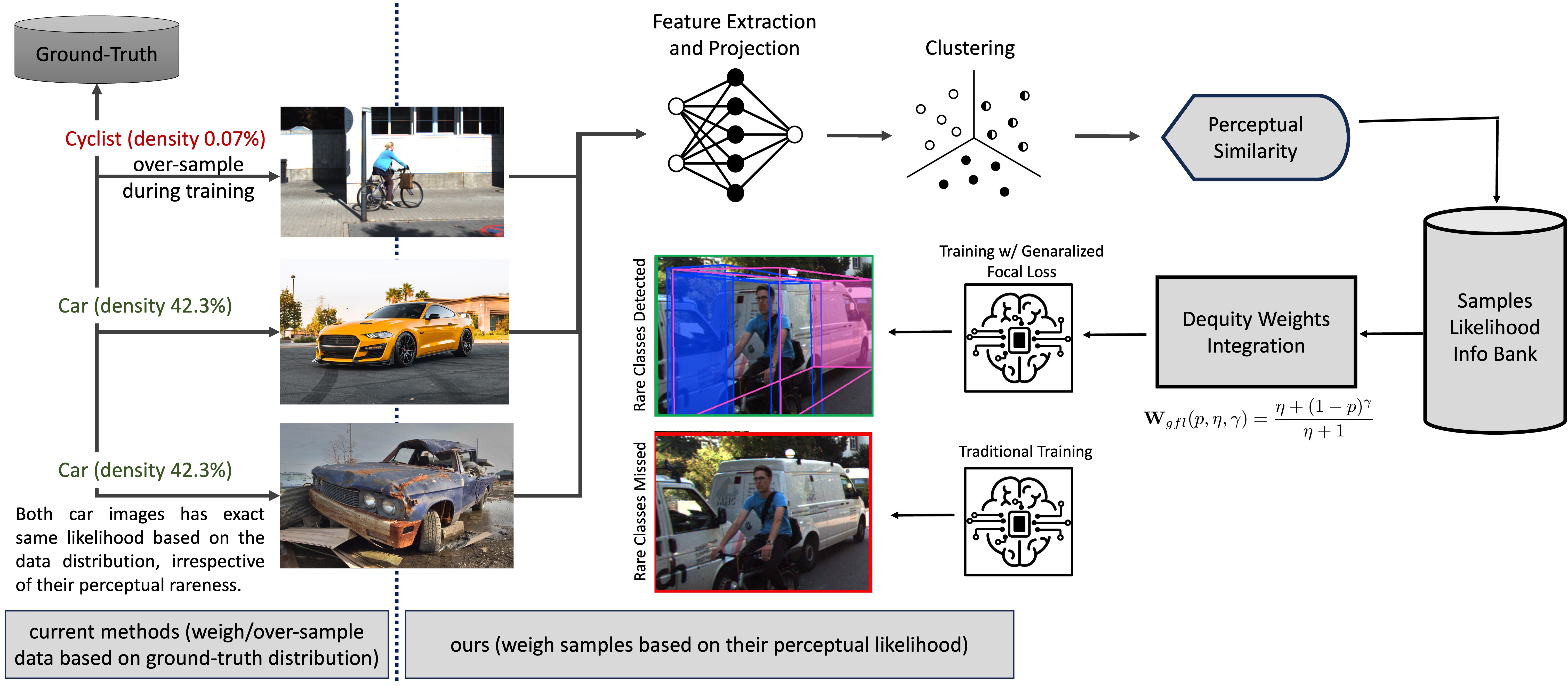
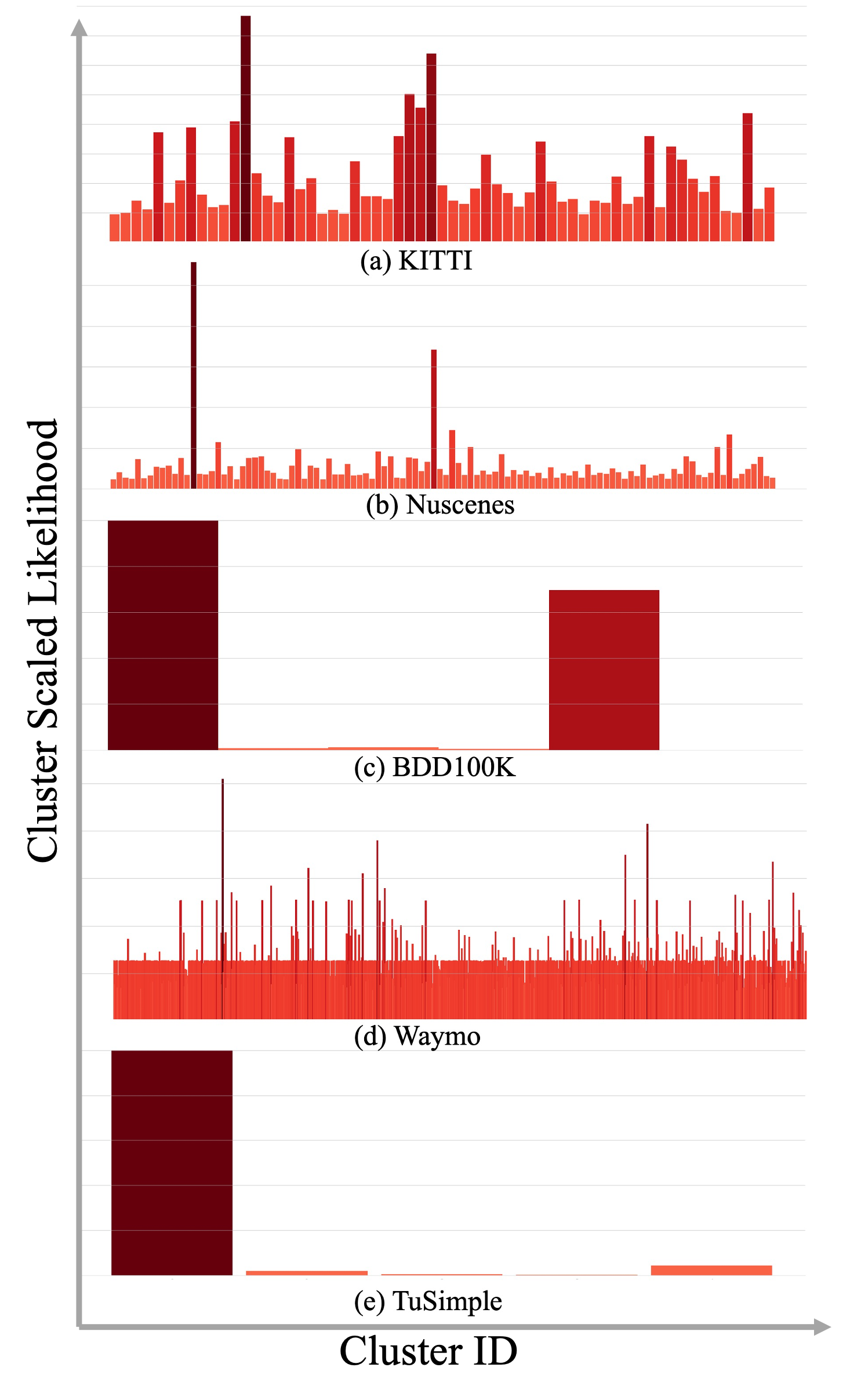
Data imbalance is a well-known issue in the field of machine learning. It is caused by a variety of factors such as the cost of data collection, the difficulty of labeling, and the geographical distribution of the data. In computer vision, bias in data distribution caused by image appearance remains highly unexplored. This paper presents a novel method for addressing data imbalance in the field of machine learning, specifically in the context of 3D object detection in computer vision. The proposed method involves weighing each sample differently during training according to its likelihood of occurrence within the dataset, which improves the performance of state-of-the-art 3D object detection methods in terms of NDS and mAP scores.
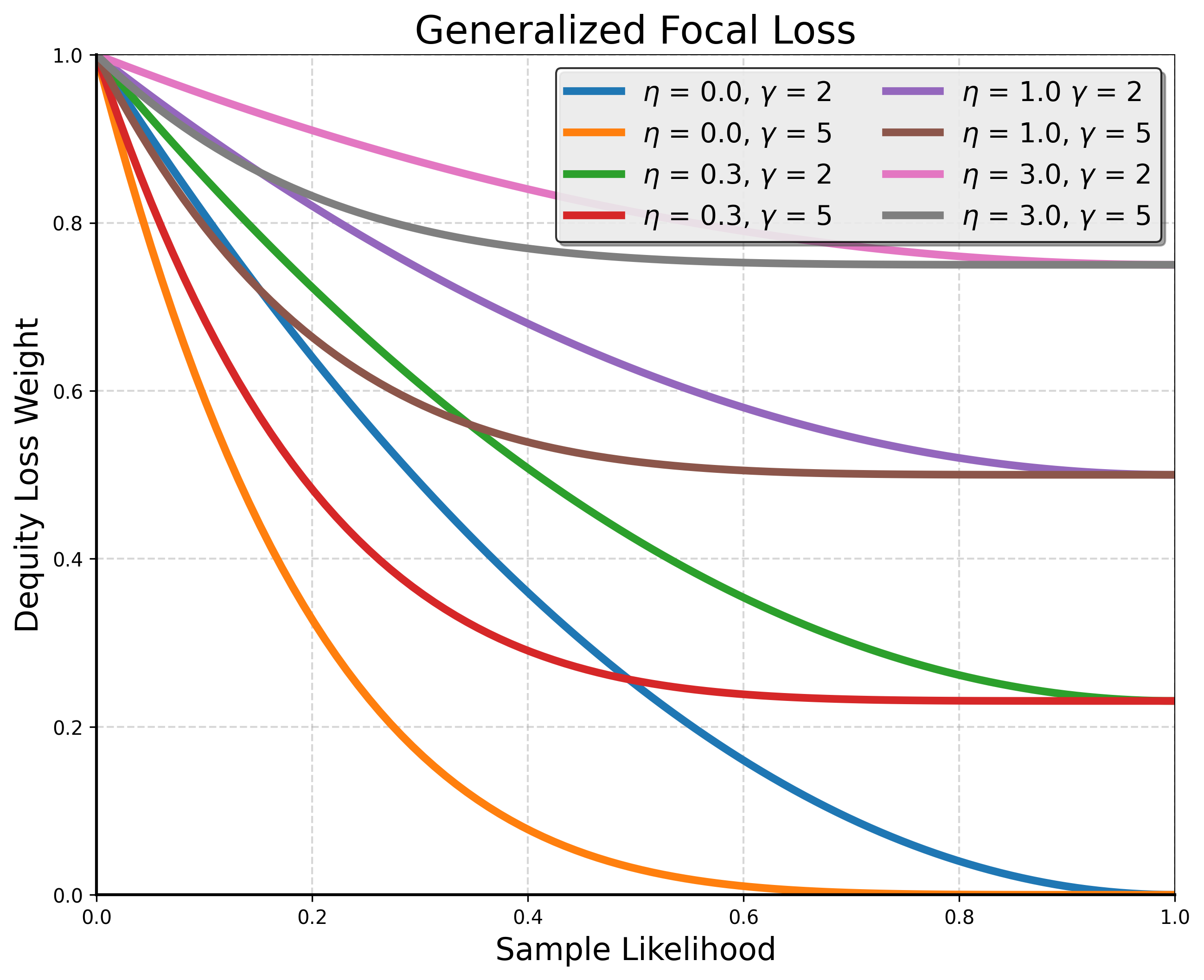
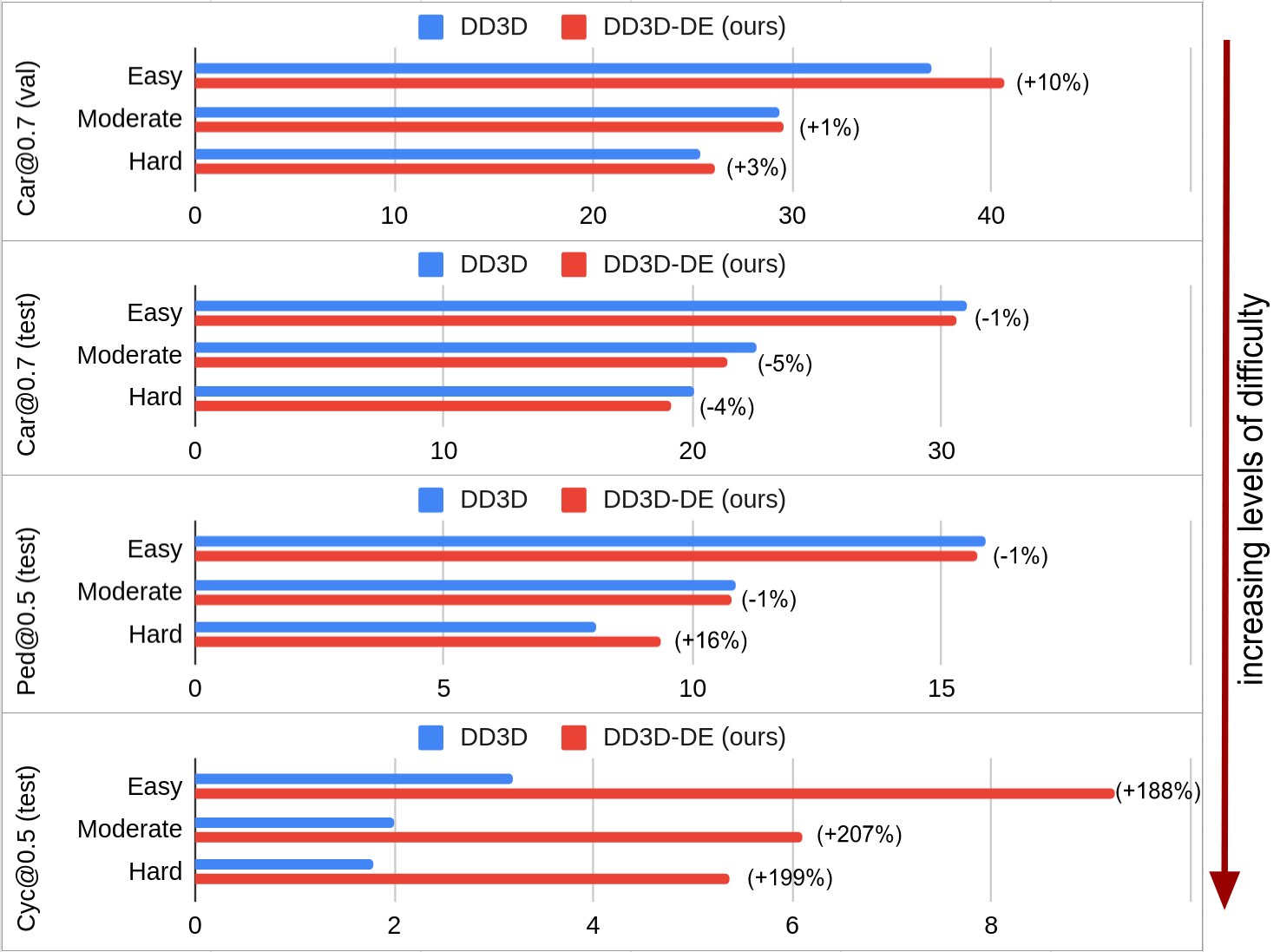
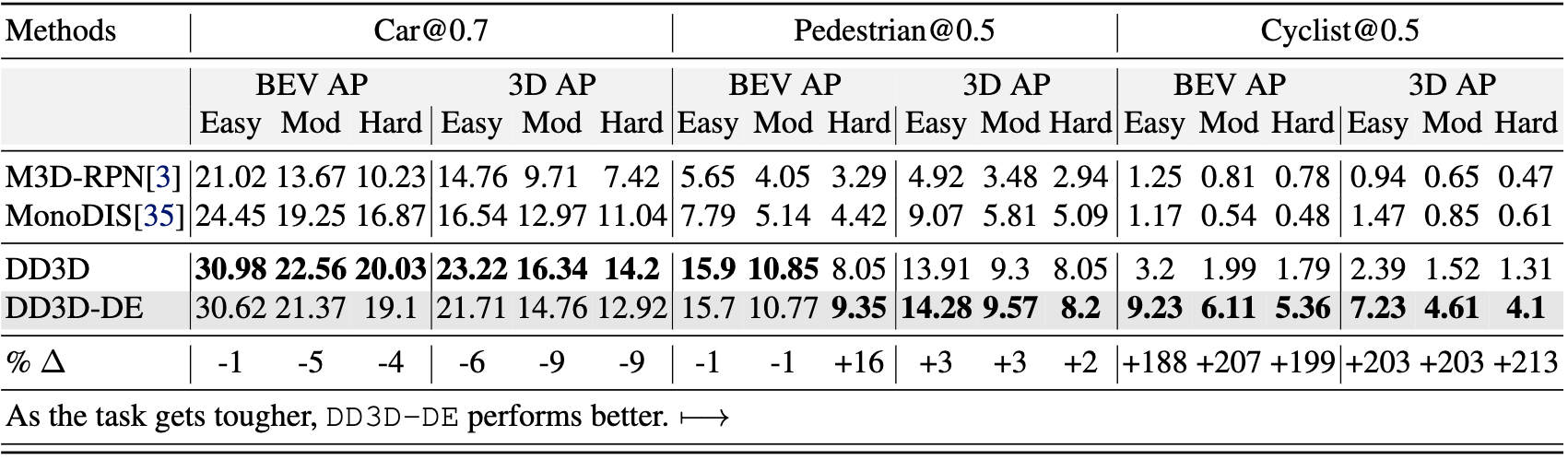
The effectiveness of the proposed loss function, called Generalized Focal Loss, was tested on two autonomous driving datasets using two different state-of-the-art camera-based 3D object detection methods. The results show that the loss function is particularly effective for smaller datasets and under-represented object classes.